Python有两个很好用第三方模块requests库和beautifulsoup库,简单学习下模块用法:
requests模块
标准库中提供了:urllib、urllib2、httplib 等模块以供Http请求,使用起来较为麻烦。 requests是基于Python开发的HTTP第三方库,在Python内置模块的基础上进行了高度的封装,使用了更简单,代码量更少。
requests 的api主要包括了八个方法:
def get(url, params=None, **kwargs):
def options(url, **kwargs):
def head(url, **kwargs):
def post(url, data=None, json=None, **kwargs):
def put(url, data=None, **kwargs):
def patch(url, data=None, **kwargs):
def delete(url, **kwargs):
#上面方法都是基于request方法实现的(method参数)
def request(method, url, **kwargs):
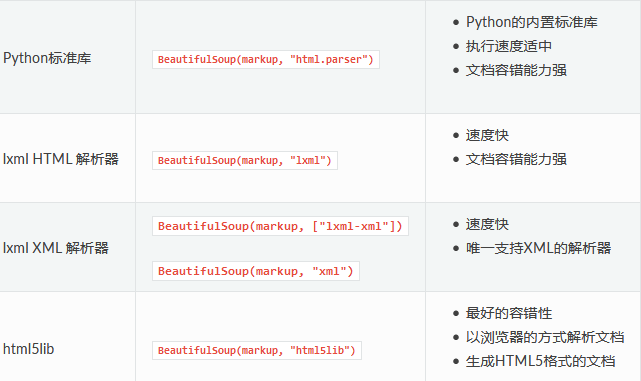
BeautifulSoup模块
BeautifulSoup模块是一个可以从 HTML或XML 文件中提取数据的Python第三方库。 它将一个html或xml字符串(或文档句柄)文档被转换成Unicode,利用解析器来解析这段文档。
BeautifulSoup 支持几种不同的解析器:
-
python标准库中的html.parser
-
第三方库lxml-html
-
lxml-xml
-
html5lib
爬虫应用: 预约空闲的羽毛球馆时间
import requests as rq
from bs4 import BeautifulSoup as bs
import datetime
debug = True
place=["753"] # 羽毛球场地编号
days=3 # 检查近3天的空闲时间
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.108 Safari/537.36',
}
for id in place:
for day in range(1,days+1):
daytime = (datetime.date.today() + datetime.timedelta(day)).strftime("%s")
url = f"https://xihuwenti.juyancn.cn/wechat/product/details?id={id}&time={daytime}"
if debug: print(url)
result = rq.get(url,headers)
soup = bs(result.content.decode(), "lxml")
results = soup.find_all('li', attrs={"class":"can-select"})
for i in results:
if i['data-start'] == "12:00" or i['data-start'] == "18:00":
print(f"{i['data-hall_name']}, {i['data-start']},{i['data-end']}")
返回查询结果
https://xihuwenti.juyancn.cn/wechat/product/details?id=753&time=1738598400
1号场, 12:00,13:00
2号场, 12:00,13:00
https://xihuwenti.juyancn.cn/wechat/product/details?id=753&time=1738684800
1号场, 12:00,13:00
3号场, 12:00,13:00
5号场, 18:00,20:00
6号场, 18:00,20:00
https://xihuwenti.juyancn.cn/wechat/product/details?id=753&time=1738771200
2号场, 12:00,13:00
5号场, 12:00,13:00
6号场, 12:00,13:00
1号场, 18:00,20:00
2号场, 18:00,20:00